An analysis of Cluster Protocol's transformative Proof of Compute protocol and its potential role in disrupting the Compute marketplace by offering a decentralized alternative.
Jun 11, 2024
13 min Read

Introduction
The article discusses Cluster Protocol's unique "Proof of Compute" protocol that promises to ignite an intelligent movement of compute sharing where individual players from around the world will utilize its decentralized compute sharing platform to access high quality, data secured and effective compute resources to Train and Deploy AI models.
This beginner friendly article begins by fostering an understanding of Consensus Mechanism, a fundamental concept to Blockchain. Later, the article discusses Cluster Protocol's PoC mechanism, how it is operated and how the end-user can expect to indulge with it.
In this exciting world of Blockchain technology, Cluster Protocol is more than just an infrastructure, it is a movement towards revolutionizing data sharing, compute resources sharing, decentralization, and the development of AI.
*To begin with, let us understand Consensus Mechanisms.*
Consensus mechanism
What is a Consensus Mechanism?
The Consensus Mechanism of a Blockchain is a predefined set of rules of how the participants in that blockchain will come to an agreement.
Consensus mechanisms act as the backbone of the blockchain ecosystem and ensure its proper operability. To put it simply, consensus stands for "an agreement", and "mechanism" stands for "A system or process of doing tasks". Together, "Consensus Mechanism" can be interpreted as "the system of coming to an agreement", in relation to the participants of the particular blockchain.
Specifically, Consensus mechanisms primarily focus on achieving agreement among nodes on the state of the blockchain, especially on the validity and ordering of transactions. However, they also inherently involve some additional rules and factors that are crucial for the overall functioning of a blockchain.
In essence, Consensus Mechanisms aim to effectively respond to the Byzantine general's problem, which is a computer science concept describing the difficulty of coming to a consensus in decentralized systems. By having pre established consensus mechanisms, blockchains can outline how their system operates, offers incentives, protects against fraud, all while remaining truly decentralized.
How do they operate?
To best understand Consensus Mechanisms and their fundamental role in Blockchain, let us understand in brief how a consensus mechanism is implemented with respect to approving a transaction on the Blockchain -
1. Proposal of a New Block
Initiation: A node (validator or miner) creates a new block containing a set of transactions.
Broadcasting: This proposed block is broadcast to all nodes in the network.
2. Validation of the Block
Verification: Nodes receive the proposed block and independently verify its validity. This involves checking the correctness of transactions, ensuring no double-spending, and confirming that the block meets the protocol rules (e.g., proper format, correct proof of work/stake).
This is done individually on every node, and there can be thousands of nodes on a Blockchain depending on its size.
3. Consensus Protocol Execution
Voting Mechanism: Nodes participate in a voting process, which can vary based on the specific consensus mechanism (e.x., Proof of Work, Proof of Stake, etc.).
Proof of Work (PoW): Miners compete to solve a cryptographic puzzle. The first to solve it gets to propose the next block.
Proof of Stake (PoS): Validators are chosen based on the number of coins they hold and are willing to "stake" as collateral. A chosen validator proposes a new block, which other validators vote on. The block is added if it receives enough votes.
4. Block Addition to the Blockchain
Block Acceptance: Once the block is validated and consensus is achieved, it is added to the blockchain. The Blockchain is immutable, and hence this transaction remains "on chain" forever.
Broadcast of New State: The updated blockchain is then broadcast to all nodes, ensuring that all nodes have the latest version of the blockchain.
Upon completion, the promised incentives are distributed to the nodes that participated in the process. For e.g., miners in PoW are rewarded with newly minted cryptocurrency, or transaction fees for their efforts in maintaining the network.
##Verifiable Compute##
Verifiable compute is a system and method of verifying the legitimacy of a computational task in which a party with weak GPU capacity can offload computational tasks to a larger, more powerful GPU processor who performs the computational task on its behalf.
Traditionally such a role has usually been played by institutional providers like AWS or Google cloud, but in recent times, the industry has seen disruption by decentralized protocols offering a much better, secure and cheaper alternative to centralized and institutional cloud providers.
One of the primary issues faced by parties that are weak in computational prowess is their inability to store large amounts of data. Computation by itself is quite simple and less resource intensive but storing large amounts of data requires significant resources and hence smaller entities are forced to outsource this task to a third-party like AWS.
In the current state of the art centralized compute sharing, the main concerns are cost and data privacy. Upcoming decentralized protocols offer both lower costs and better data privacy and protection by distributing the task of compute allocation throughout nodes that are based in different parts of the world.
Verifiable compute in a decentralized framework is a system which facilitates this allocation of compute and ensures that all compute tasks are performed properly and legitimately. Such a system removes the need for a central authority and enables two untrusting parties to form a contract by trusting and relying on the protocol itself. The verification is done in a way to protect data privacy while simultaneously ensuring that legitimate work is performed.
One such method of verification using encryption is the Homomorphic Public Key Cryptography (PKC). To explain simple, PKC is a method by which a computed work can be verified by revealing a little string of information from the outcome. In this way, the verifier can successfully verify the task without getting to know the details.
For example, given two ciphertexts E(a) and E(b), a homomorphic encryption scheme allows computation of E(a+b) or E(a⋅b) for example, without decrypting a and b.
Homomorphic public key cryptography ranges from Partial Homomorphic Encryption to Fully Homomorphic Encryption (FHE).
FHE is the most advanced version and supports unlimited operations of both addition and multiplication on ciphertexts, enabling complex computations on encrypted data.
Some of the use cases of PKC include its application in secure data processing as already discussed above, Zero-Knowledge Proofs (ZK-SNARKS), and even civilian use cases such as its utilitarian purpose in ensuring fairness in voting systems. To understand PKC in further depth, the paragraph below provides a further detailed analysis.
Detail on Homomorphic Public Key Cryptography (PKC)
Homomorphic public key cryptography (PKC) leverages certain functions, F, that allow the computation of F on the product of two values, xy, without knowing one of the values.
Examples include scalar multiplication of elliptic curve points and exponentiations in a prime field. This property has been used to create compact zero-knowledge proofs of computation integrity, starting with [Gro10], which had quadratic proving time in relation to |C|. This was impractical until the development of the Pinocchio scheme [PHGR13] and its derivatives [BCG+13, Gro16], known as ZK-SNARKs.
These schemes require computations to be expressed as arithmetic circuits or systems of polynomial constraints of degree 2, such as:
V(X)⋅W(X)=U(X)V(X) \cdot W(X) = U(X)V(X)⋅W(X)=U(X)
where V, W, and U are linear functions of internal and input variables. The resulting proofs are very small (less than 1KB) and independent of the circuit size, but require a trusted setup. Specifically, a trusted party must compute the polynomial constraints on a secretly chosen input, create a proving key, and then destroy the secret. If the secret is leaked, an adversary can forge a proof.
ZK-SNARKs became popular through their use in the privacy-focused cryptocurrency Zcash [Zca18], where transaction details are hidden but correctness is ensured by ZK-SNARKs. The trusted setup for ZK-SNARKs was conducted as a secure multiparty computation, ensuring security as long as at least one participant destroyed their secret.
##Proof of Compute in DePIN infrastructures. Cluster Protocol's Model##

What is Cluster Protocol's "Proof of Compute" consensus mechanism?
The Fundamental structure of Cluster Protocol is designed to create a dynamic, decentralized AI ecosystem.
*Here's how each part plays a role in order:*
Cluster Protocol Core
At the heart of the ecosystem is the Cluster Protocol itself, facilitating Proof of Compute for transactions, providing access to AI models, solutions, and datasets, as well as computational resources.
Contribution and Earnings
Researchers/Contributors: These are the innovators who deploy AI models and datasets within the Cluster Protocol, earning rewards for their contributions.
Delegators: Participants who stake Cluster Protocol Tokens ($CP) and delegate their computational resources to the network, gaining returns for their investment.
Operators: They are the computational workforce, staking $CP to provide processing power to the network and earning from its utilization or through incentivized staking during idle times.
AI Model Deployment
Decentralized AI Models: A library of AI models is available for deployment, ensuring a wide variety of tools for different tasks.
AI Engineers: The architects of the AI models, who utilize the protocol's resources to create, train, and deploy new models.
Data Sharing and Validation
Decentralized Data Sharing: Data providers contribute new datasets or validate existing ones, enriching the data pool available for AI training and execution.
Decentralized Datasets: The compilation of datasets available for use, fostering innovation and accuracy in AI model development.
Execution and Usage
AI Executive Model: This component seems to manage the execution of AI tasks, ensuring that the AI models are operating efficiently within the ecosystem.
Cluster Arena: The user interface where all participants interact, selecting or uploading models, leveraging computational resources, and orchestrating tasks using Kubernetes for seamless execution.
The Customer
Users: The beneficiaries of the Cluster Protocol who can stake $CP to gain benefits such as priority computing access, extra incentives, and discounted prices for services provided by the Cluster Protocol.
##Cluster Protocol's Blockchain##
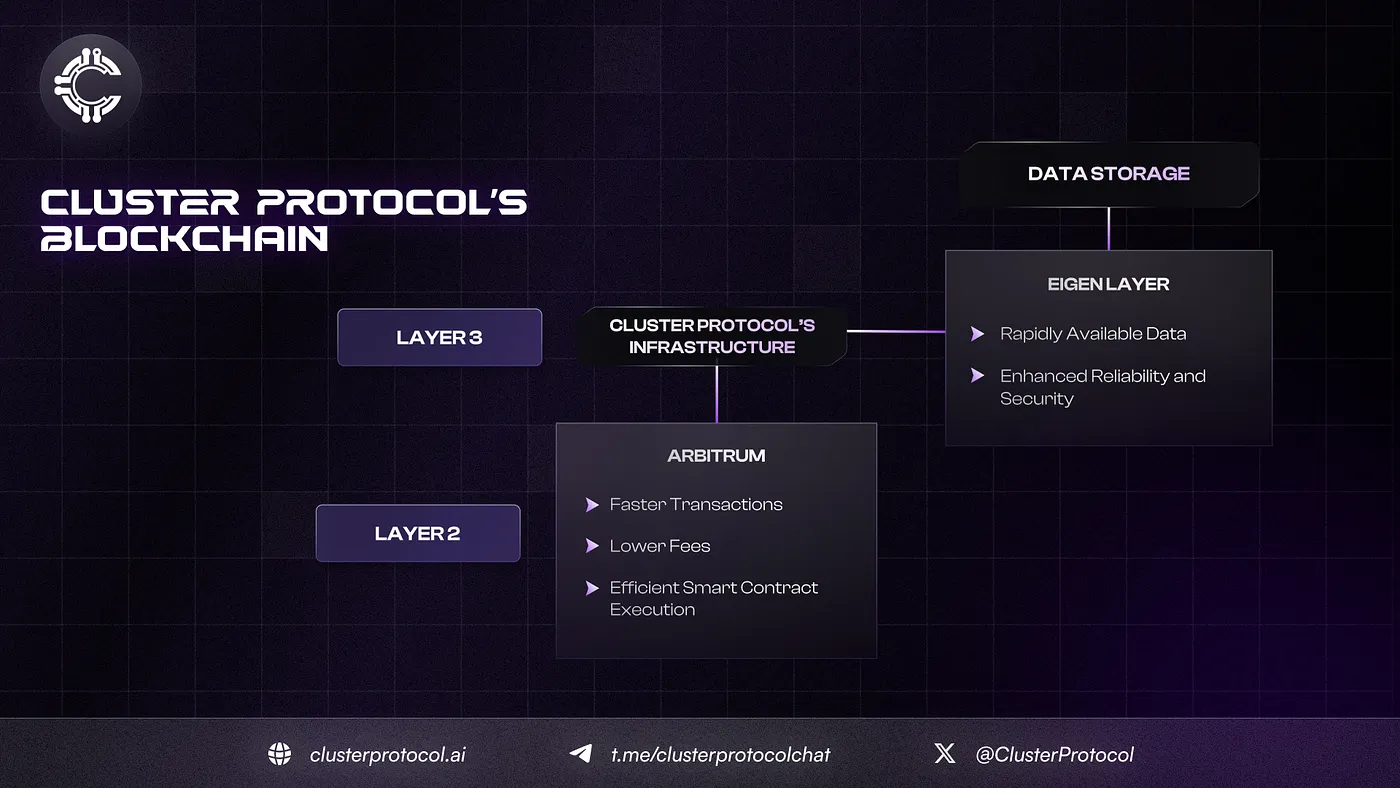
The Cluster Blockchain introduces an inventive Layer 3 architecture that functions on top of Arbitrum and integrates EigenLayer for Data Availability. This strategy strengthens the protocol's security, transparency, and efficiency by harnessing the capabilities of both Arbitrum and EigenLayer.
Utilizing Arbitrum's Layer 2 solution, the Cluster Protocol gains advantages such as expedited transactions and reduced fees compared to Ethereum's Layer 1. Furthermore, Arbitrum's rollup technology enables scalable and efficient execution of smart contracts, making it an ideal base for the advanced features of the Cluster Protocol.
EigenLayer operates as the Data Availability layer, ensuring seamless accessibility and secure storage of all data necessary for the protocol's operations. This configuration enhances the integrity and reliability of the network by furnishing a robust and decentralized solution for data storage and availability.
Background: What are the different Layers in a Blockchain ecosystem?
For the new readers, let us briefly understand what Layers are in Blockchain technology:
Layer 1- Protocol Layer
First layer protocols are the foundational blockchains that are the fundamental structure such as Bitcoin and Ethereum. These contain original rules, processes and the consensus mechanism upon which the blockchain is to operate.
Layer 2- Enhancements
The second layer is built on top of the first layer protocols and acts as an enhanced add-on, providing improvements in aspects of the Blockchain that the first layer lacked. This can include fixing issues to enhance scalability, ease of use, interoperability, security and much more.
Many L2 protocols are off-chain with emphasis on scaling and security. An example of this is Bitcoin's Layer 2 solution "Lightening" which solves the blockchain's slow transaction speeds by offering a way to transact more efficiently using Bitcoin.
Layer 3- Expansion
In essence, Layer 3 protocols generally aim to provide extended functionality and services. By leveraging the underlying foundational L1 infrastructure and improvements from L2, L3 protocols often expand the blockchain into more complex or larger horizons.
Choice of Arbitrum (L2) instead of Ethereum (L1)
Arbitrum is a Layer 2 scaling solution for the Ethereum blockchain. Cluster Protocol's use of Arbitrum over Ethereum (L1) stems from many reasons including company goals, Arbitrum's unique selling propositions and the many other benefits offered.
In short, Arbitrum aims to address Ethereum's scalability challenges by enabling faster and more efficient transaction processing while still leveraging the security and decentralization of Ethereum's Layer 1 (L1) mainnet. Arbitrum achieves this by implementing a technique called optimistic rollups.
*Here are a few benefits of choosing Arbitrum's L2 solutions -*
Scalability
Ethereum's Layer 1 has limitations in terms of transaction throughput and processing speed. By building on Layer 2 solutions like Arbitrum, we can significantly increase the scalability of our intended application. Furthermore, Arbitrum allows for a higher volume of transactions to be processed off-chain while still benefiting from the security of Ethereum's mainnet.
Lower Fees and Faster transactions
Ethereum's Layer 1 often experiences congestion during periods of high network activity, leading to increased transaction fees. Layer 2 solutions like Arbitrum can help alleviate this congestion by moving transactions off-chain, resulting in lower fees for users and faster transaction speeds.
Compatibility
Applications built on Layer 2 solutions like Arbitrum remain almost fully compatible with Ethereum's existing infrastructure, including wallets, smart contracts, and other decentralized applications (DApps). This ensures a seamless user experience and interoperability with the broader Ethereum ecosystem. All of these qualities further enhance further adoption.
Security
Although Layer 2 solutions operate off-chain, they rely on Ethereum's mainnet for security and finality. Arbitrum employs a mechanism known as optimistic rollups, which allows for efficient dispute resolution and ensures the integrity of transactions through periodic verification on Ethereum's mainnet.
Why EigenLayer as the primary data storage choice?
EigenLayer is a data availability layer that primarily offers two main incentives to Cluster Protocol. First, the rapidly accessible data and second, the ability to store it securely.
Today, Eigenlayer serves as a critical component within blockchain and decentralized systems, particularly in scenarios where efficient and reliable data storage is paramount.
*These qualities significantly enhance Cluster Protocol's infrastructure for the reasons specified below -*
Data Availability and Accessibility
EigenLayer focuses on ensuring the availability and accessibility of data necessary for the operations of a protocol or application. This includes transaction data, smart contract states, user balances, and any other relevant information stored on the blockchain.
Security and Integrity
EigenLayer plays a crucial role in maintaining the security and integrity of data stored within the blockchain network. It employs robust cryptographic techniques and decentralized storage solutions to safeguard data against tampering, unauthorized access, and data loss.
Decentralization
EigenLayer promotes decentralization by distributing data across multiple nodes or storage providers within the network. This distributed architecture ensures that no single entity has control over the entire dataset, enhancing resilience and mitigating the risk of data censorship or manipulation.
Reliability and Redundancy
EigenLayer's premium storage practices ensure that data is reliably stored and redundantly replicated across multiple nodes or storage locations. This redundancy helps prevent data loss or corruption in the event of node failures, network partitions, or other unforeseen circumstances.
Cluster Protocol's Proof of Compute Layers.

Cluster Protocol's Proof of Compute consensus mechanism is designed to facilitate the sharing of compute on the decentralized platform without the need of a central authority.
The two layers that operate within the consensus mechanism are the Compute layer and the Verification layer.
The Compute layer can be thought of as the "engine" of our protocol. This is where the main computational work takes place.
The verification layer as the name suggests does the task of validating a performed task in order to supply a trustless transaction between two parties.
The diagram above provides a summary of the key features of the two layers within the consensus mechanism.
##How will the user interact with Cluster Protocol's infrastructure?##
Cluster Protocol's front-end user experience is designed with particular focus on ease of use, efficiency and quality of service.
*The user process flow below outlines how a user will interact with our infrastructure in a step by step format -*
User Process Flow
1. Sign Up & Project Initiation:
- The user signs up on the Cluster Portal.
- They initiate a new AI project, define its parameters, and upload any initial data.
2. Model Selection:
- The user browses the Model Repository via the Portal.
- They select a pre-trained model best suited for their task.
- If needed, they customize the model using the Model Customization Interface.
3. Compute Allocation:
- Once the model is selected, the Resource Scheduler automatically allocates the necessary compute resources from the GPU/Compute Resources Pool.
- The Orchestration Engine provisions these resources and prepares the environment for model deployment.
4. Model Training/Deployment:
- If further training is required, the user's data is ingested into the system, and the model is trained using the allocated compute resources.
- For inference tasks, the model is deployed directly to the allocated resources for immediate use.
5. Data Processing & Analytics:
- The user's data is continuously ingested and processed.
- The Analytics Engine uses the deployed model to generate predictions or analyses.
- The user can monitor performance and results through Visualization Tools in real-time.
6. Scaling & Monitoring:
- The system monitors resource usage and scales the GPU/Compute Resources Pool up or down as needed.
- The user receives updates and alerts through the Access Portal about their project's status.
7. Insight Gathering & Reporting:
- The user evaluates the outcomes via reports and dashboards.
- They can export results, integrate them with other systems, or use them to make informed decisions.
8. Project Completion:
- Upon project completion, the user can archive the project, retain the model for future use, or decommission the resources.
##Conclusion##
The article aimed to provide the reader with an understanding of Cluster Protocol's Proof of Compute consensus mechanism and its unique potential in facilitating large scale, decentralized and global sharing of compute.
As discussed above, small players face great hurdles in storing their data, which is often resource intensive and financially taxing. Modern decentralized solutions like Cluster Protocol offer a better alternative to institutional and centralized platforms like the AWS by reducing costs, enhancing data privacy and building a trustless protocol where parties around the world can achieve their computational needs.
To establish a better foundation, the article also provided the readers with an understanding of consensus mechanisms, verifiable computation and the different layers in a blockchain. Lastly, the article provided a birds eye view of how you, as a user, will interact with Cluster Protocol's infrastructure in the very near future.
Cluster Protocol's unique "Proof of Compute" protocol is a promise towards a future where decentralized compute and data sharing is easy, effective and wide-scale. Cluster Protocol's infrastructure is a secure, efficient, and community-driven environment for AI development and deployment, with primary focus on data privacy.
Cluster Protocol supports decentralized datasets and collaborative model training environments, which reduce the barriers to AI development and democratize access to computational resources. Its innovative features, like the Deploy to Earn model and Proof of Compute, provide avenues for users to monetize idle GPU resources while ensuring transaction security and resource optimization.
Cluster Protocol provides an infrastructure to anyone for building anything AI over them. The platform's architecture also fosters a transparent compute layer for verifiable task processing, which is crucial for maintaining integrity in decentralized networks.
🌐 Cluster Protocol's Official Links: