The Data Dilemma: AI, Blockchain, and the Fight for Digital Sovereignty
Feb 18, 2025
10 min Read

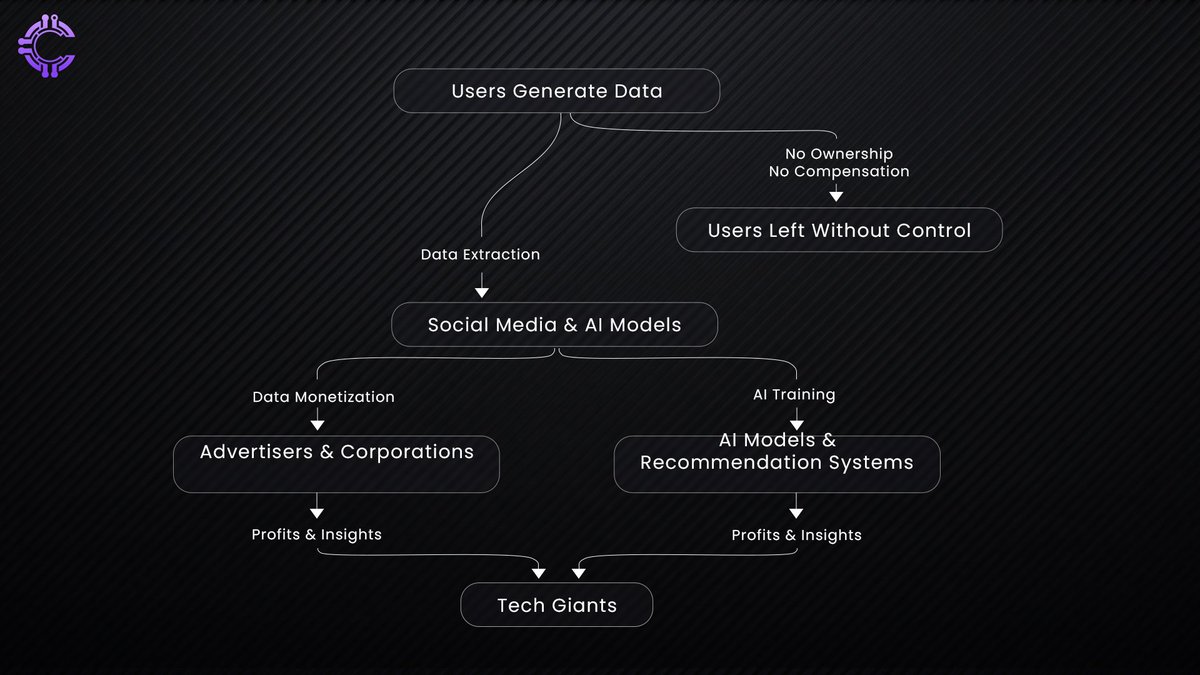
The internet was meant to be an open frontier, a space where information flowed freely, where users had control over their digital presence. But that vision faded as data became the currency of the online world, and those who controlled it became the new power brokers. Today, tech giants dictate how information is stored, accessed, and monetized, turning user-generated content into a multi-trillion-dollar industry built on one fundamental truth: attention is wealth.
In 2024, global screen time averages over six hours per day, with the U.S. surpassing seven. Every interaction, searches, posts, transactions is logged, analyzed, and fed into a system designed to maximize engagement, not user empowerment. Google, which once merely indexed the web, now dictates which content is seen and by whom. Social media platforms, under the guise of “connecting the world,” have become data extraction machines, tracking every move to refine their ad-driven models. The paradox is clear: users create the data, but they own none of it.
Controlling the Flow of Information
The promise of an open internet has eroded into a system of gatekeepers, where a handful of corporations determine what is visible, what is suppressed, and most importantly, who profits. They don’t create the data, yet they monetize every click, swipe, and interaction. They don’t produce content, yet they control its reach.
Platforms like Twitter, Instagram, and Facebook operate as walled gardens, where user-generated content fuels engagement-driven algorithms. The illusion is simple but effective: these platforms feel free, yet they extract immense value from your digital presence. You don’t pay with money; you pay with attention, and in the digital gold rush, attention is the most valuable currency of all.
AI’s Hunger for Data: The Silent Exploitation
Artificial intelligence is built on data, but AI models don’t generate it, they consume it. Every AI breakthrough, from ChatGPT to self-driving cars, relies on vast datasets harvested from the internet. Who provided this data? Users. Who benefits from it? Not users.
AI doesn’t just passively use existing data; it actively seeks more. Companies scrape social media, analyze conversations, and track engagement to refine their algorithms. Even crypto projects, like Kaito AI, have entered the space, indexing social sentiment and translating it into market signals. The problem? Users fuel these systems but have no control over how their words, interactions, and opinions are used.
It’s a strange paradox - AI cannot exist without human-generated data, yet those humans have no claim over its value. The question isn’t just who owns the data; it’s who should benefit from it? AI has the potential to revolutionize i ndustries, but if it remains locked within centralized platforms, we’re simply repeating the same cycle of exploitation. The real challenge is not just building better AI but ensuring it serves the people who power it.
Breaking the Chains: How Crypto and Web3 Are Reclaiming Data Ownership
For too long, the internet has operated under a feudal system, users generate the data, corporations own it, and AI systems refine it into intelligence that fuels trillion-dollar industries. But a new movement is emerging. A movement that challenges the status quo, shifting power away from centralized platforms and into the hands of individuals.
This is the rise of decentralized data layers, the foundation of a new digital economy where data is not extracted but exchanged, not hoarded but monetized.
Instead of tech giants acting as middlemen, blockchain-based protocols are creating decentralized marketplaces where users control access to their own information.
Imagine an internet where your browsing habits, social media interactions, and even the biometric data from your smartwatch belong to you and you alone. No silent tracking, no opaque monetization, no hidden algorithms deciding how your data is used. Just pure, sovereign control.
The Data Economy: From Exploitation to Ownership
If data is the new oil, why aren’t those producing it profiting from it? The answer lies in who controls the infrastructure. In the traditional internet model, platforms like Google and Facebook extract data from users, refine it with AI, and sell it to advertisers. In Web3, data itself becomes an asset that individuals can own, trade, and monetize.
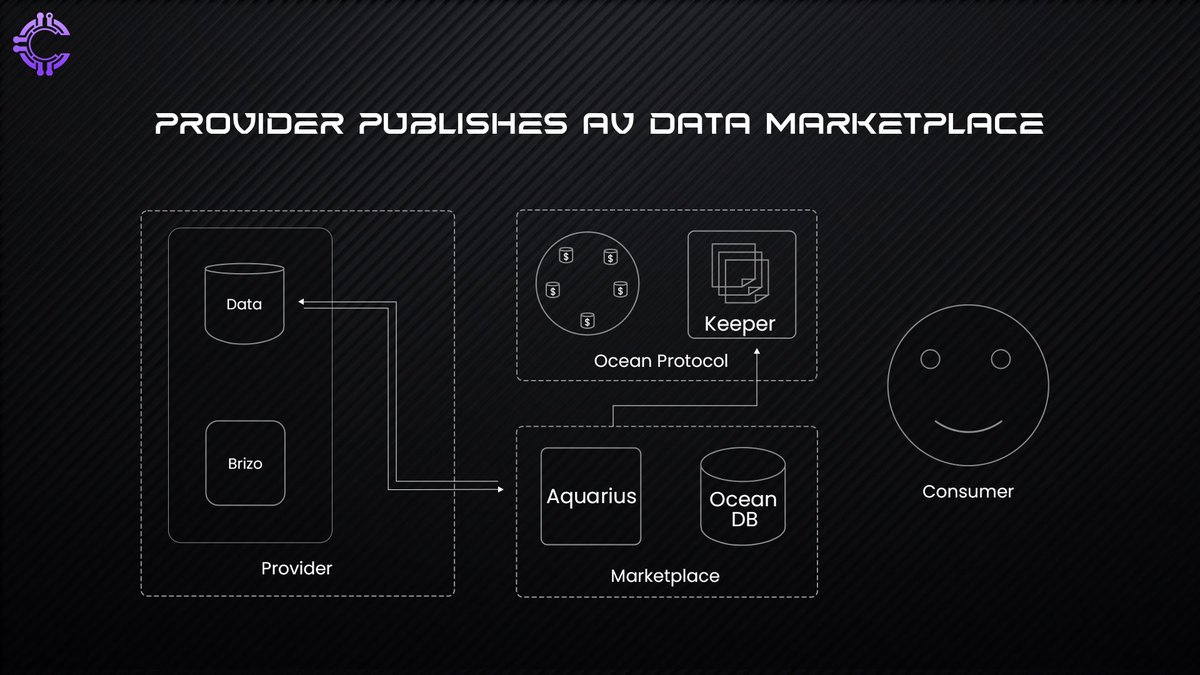
One of the most promising innovations in this space is Ocean Protocol, a decentralized data marketplace that allows individuals and businesses to share, sell, or license their data while retaining control over access conditions. Instead of handing over raw data to centralized platforms, users tokenize their datasets through datatokens (ERC-20 tokens), which function as access keys to specific datasets. This means that instead of simply giving their data away for free, users can now set their own terms—deciding who can use it, under what conditions, and at what price.
The types of data traded on Ocean are diverse:
Public Data: Open datasets like weather information, economic indicators, and demographic statistics. These are invaluable for AI research and predictive modeling.
Private Data: Sensitive information like medical records, financial transactions, IoT sensor data, and behavioral analytics. These require stringent privacy controls but are among the most valuable datasets for AI and research.
Beyond monetization, Ocean’s Compute-to-Data feature is a game-changer. Instead of exposing raw data, AI models can perform computations on the data without ever moving or storing it elsewhere. This ensures that privacy remains intact while still allowing AI systems to extract valuable insights. Imagine a pharmaceutical company needing access to rare disease data rather than extracting personal medical records, they can train AI models directly on patient data in a privacy-preserving manner.
The internet we know today thrives on data hoarding. The internet of the future will thrive on data sovereignty.
AI, Blockchain, and the Data Wars Ahead
AI is hungry, starving, even. The demand for high-quality, real-time data to train models and autonomous agents is skyrocketing. But as concerns over privacy, data bias, and ethical AI development grow, simply scraping the internet and siphoning user data is no longer sustainable.
With blockchain-based data marketplaces, AI can access structured, high-quality data in a way that is transparent and ethical. Instead of hidden data pipelines that exploit users, AI models will operate within decentralized frameworks where individuals consent to their data being used and are compensated for it. Synthetic data is also on the rise, offering a privacy-preserving way to train AI without exposing real user information.
The real question isn’t whether AI needs data, it’s who gets to decide how that data is used? If Web3 succeeds, the answer won’t be corporations. It will be the people. The battle for data ownership is just beginning, and this time, users have the tools to fight back.
The Data Dilemma: Privacy, AI, and the Battle for Verifiability
The internet has always walked a fine line between accessibility and control. Every interaction, every search, and every digital footprint is collected, analyzed, and repurposed, fueling AI models that are getting smarter by the day. But while AI thrives on this data, individuals have little say in how their personal information is used, stored, or monetized.
This is the core of the data dilemma: the need for AI to process massive datasets versus the fundamental right to privacy. AI can’t function without data, yet unrestricted data collection leads to surveillance, manipulation, and ethical concerns. With deepfakes, misinformation, and AI-driven automation accelerating, verifiability has become just as crucial as privacy. It’s no longer just about who owns the data, it’s about who controls the narrative.
Balancing Privacy and AI Development
AI and privacy have traditionally been at odds. The more data an AI model has, the more accurate it becomes but at the cost of personal privacy. To address this, new approaches are emerging that allow AI to function without directly accessing raw data.
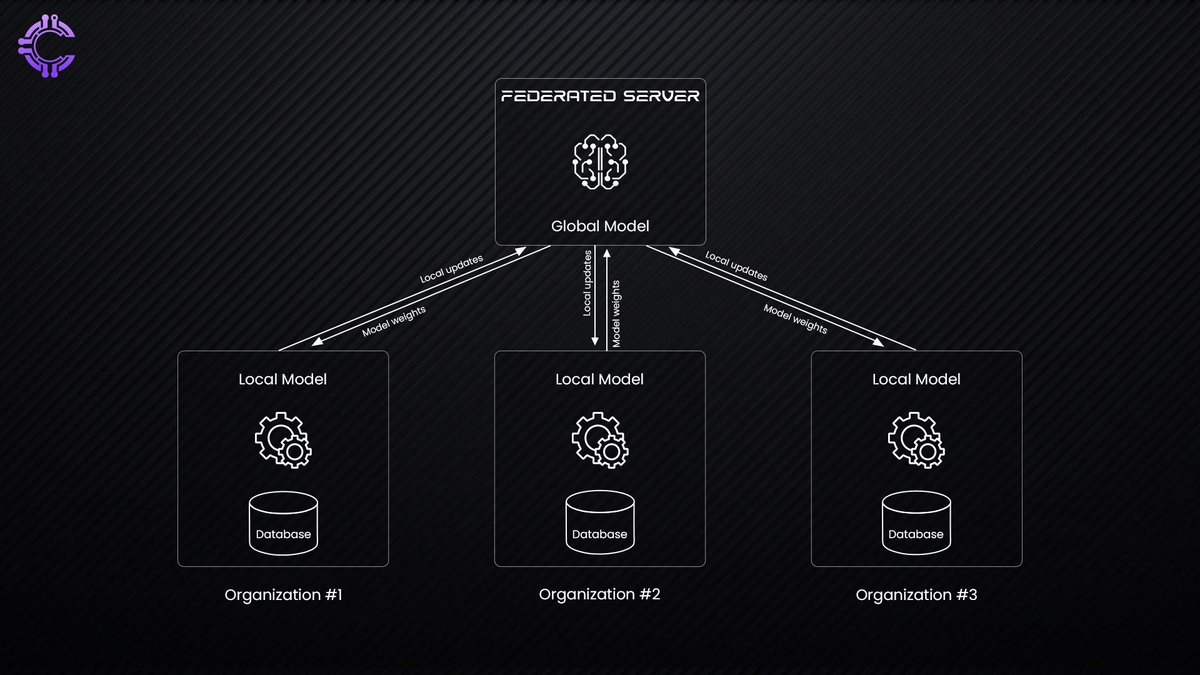
Federated learning is one such technique. Instead of centralizing data in massive repositories, AI models are trained on individual devices, with only insights, rather than raw data being shared. This method is already being used in healthcare and finance, where privacy concerns are paramount.
Then there’s zero-knowledge proofs (ZKPs), which allow one party to prove something is true without revealing the underlying data. This is especially relevant in AI training, where ensuring data authenticity without compromising privacy is becoming a top priority.
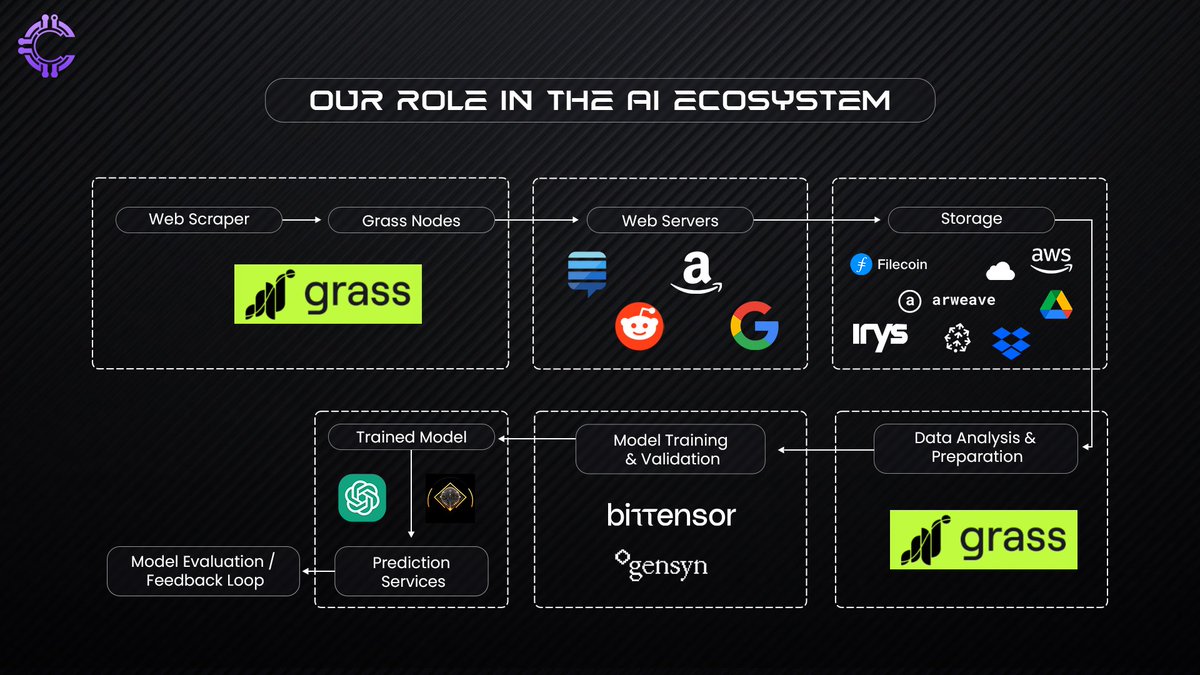
Projects like Grass are taking a different approach using publicly available web data to create structured datasets for AI training. Instead of relying on corporate-controlled datasets, Grass enables users to contribute idle internet bandwidth to scrape only publicly accessible information. This ensures AI models have access to real-time, structured data without infringing on personal privacy. By integrating ZKPs, Grass also ensures that the integrity of collected data is verifiable, making it a potential alternative to centralized data collection.
AI x Blockchain: Building a Framework for Trust
AI’s growing influence means trust and verifiability are no longer optional, they are essential. Deepfakes, AI-generated misinformation, and biased algorithms have made it increasingly difficult to differentiate between truth and manipulation. Blockchain presents a potential solution: an immutable, transparent framework where AI models can operate within verifiable constraints.
Zero-knowledge proofs (ZKPs) are already proving their worth in AI applications. For instance, zkMe’s zkKYC solution allows identity verification without exposing personal information - a breakthrough for privacy-focused AI development.
Similarly, trusted execution environments (TEEs) create secure hardware-based enclaves where AI computations can occur without external interference.
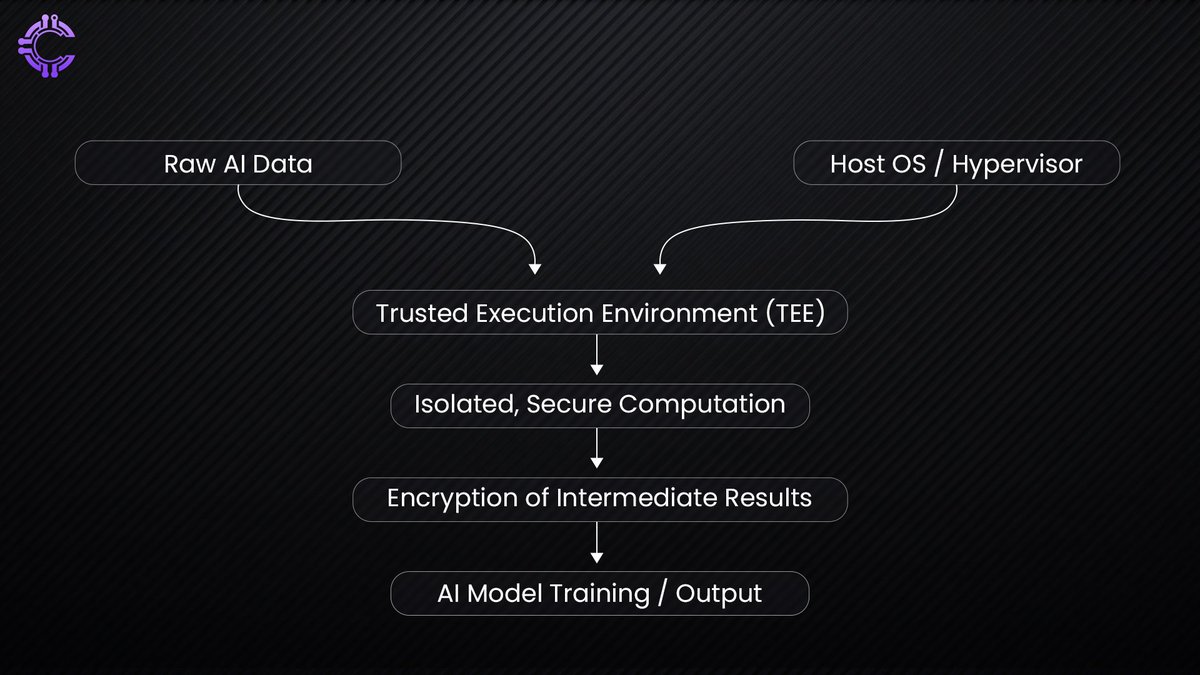
Beyond identity verification, fully homomorphic encryption (FHE) is emerging as a way for AI to perform computations on encrypted data without ever decrypting it. This could redefine how personal and corporate data is processed, ensuring privacy without limiting AI’s ability to analyze and learn.

As AI continues to evolve, blockchain will likely play a central role in making these systems accountable. The goal isn’t just to build more advanced AI, it’s to build AI that operates within a framework of transparency, privacy, and user control. The future of AI isn’t just about intelligence, it’s about ensuring that intelligence remains verifiable and ethical.
The AI-Powered Data Economy: Ownership or Exploitation?
AI is no longer just a tool, it’s becoming an autonomous force, capable of processing, analyzing, and trading data without human input. AI-driven data markets are emerging, but who truly benefits? As AI integrates deeper into daily life, digital identity is no longer just about access but control.
The future of agents are self-sovereign identities, where individuals own their data, but the risks are clear - AI is already being weaponized for fraud, surveillance, and manipulation. The future hinges on whether AI and blockchain empower people or entrench control. This isn’t just a technological shift, it’s an ethical one.
Conclusion
The fight for data sovereignty is no longer a distant concept—it is an urgent necessity. AI is evolving rapidly, but its dependence on centralized data sources raises deep ethical concerns. Who controls the datasets? Who ensures the integrity of AI-generated content? And more importantly, who benefits from the intelligence derived from user-generated data?
Blockchain and decentralized AI solutions offer a path forward. By integrating zero-knowledge proofs, trusted execution environments, and decentralized identity frameworks, we can ensure that AI operates transparently, ethically, and within user-defined boundaries. Decentralized data markets, like Ocean Protocol, show that it is possible to share and monetize data without compromising privacy. Innovations in federated learning and Compute-to-Data are proving that AI can be trained without direct access to raw datasets.
The future of AI and data isn’t just about technology - it’s about control. Either we build systems that empower individuals, or we allow AI and data monopolies to entrench their dominance further. The choice is ours. The era of blindly surrendering data to centralized entities must end. It’s time to reclaim ownership, ensure accountability, and reshape the digital economy in a way that benefits everyone, not just a privileged few.
About Cluster Protocol
Cluster Protocol is the co-ordination layer for AI agents, a carnot engine fueling the AI economy making sure the AI developers are monetized for their AI models and users get an unified seamless experience to build that next AI app/ agent within a virtual disposable environment facilitating the creation of modular, self-evolving AI agents.
Cluster Protocol also supports decentralized datasets and collaborative model training environments, which reduce the barriers to AI development and democratize access to computational resources. We believe in the power of templatization to streamline AI development.
Cluster Protocol offers a wide range of pre-built AI templates, allowing users to quickly create and customize AI solutions for their specific needs. Our intuitive infrastructure empowers users to create AI-powered applications without requiring deep technical expertise.
Cluster Protocol provides the necessary infrastructure for creating intelligent agentic workflows that can autonomously perform actions based on predefined rules and real-time data. Additionally, individuals can leverage our platform to automate their daily tasks, saving time and effort.
🌐 Cluster Protocol’s Official Links: